Benchmark and deploy Liquid AI models instantly across real devices through Melange, in collaboration with Qualcomm Technologies.

The future of AI isn't in the cloud. It is in the palm of your hand, in your car, and embedded in the world around you. But getting high-performance AI to run locally on edge devices has historically been a fragmented, painful process for developers.
Today, we are thrilled to announce that ZETIC is collaborating with Qualcomm Technologies and Liquid AI to change that. We are bringing seamless, zero-friction on-device AI deployment to Qualcomm's industry-leading platforms.
The On-Device Future: CPU, GPU, and NPU Working Together
While cloud compute has dominated AI deployment, the real frontier is running AI directly on the devices people already carry. Smartphones, laptops, and edge hardware today ship with powerful CPUs, GPUs, and dedicated Neural Processing Units, each suited for different workloads.
Through this collaboration, ZETIC is integrating its deployment technology seamlessly with Qualcomm's platforms, including the Snapdragon® 8 Elite Gen 5 (mobile) and the Snapdragon® X2 Elite (compute). Rather than locking developers into a single compute path, Melange intelligently routes each workload to the most appropriate hardware unit, whether that is the CPU, GPU, or Qualcomm's Hexagon NPU, based on the model, the quantization format, and the target device.
This means developers are no longer making low-level hardware decisions manually. Melange handles the orchestration, and developers ship faster. What used to take an ML engineering team weeks of low-level optimization can now be executed by a single developer in minutes.Developers can extend their deployment to additional hardware platforms without changing their existing workflow. The same integration, the same code, just broader reach.
Evaluating Hardware Performance & Choosing the Right Model
Before deploying a model on-device, developers need to answer two questions: which model fits their application, and how that model actually performs across real devices. ZETIC benchmarks every model across 100+ devices spanning Android and iOS, from flagship to budget to legacy hardware.
To provide a realistic baseline for these decisions, we tested several widely adopted, industry-standard AI models available directly through the ZETIC public library. Here is a look at the performance profiles when evaluating these workloads, comparing standard on-device CPU execution against the dedicated Hexagon NPU powered by ZETIC:
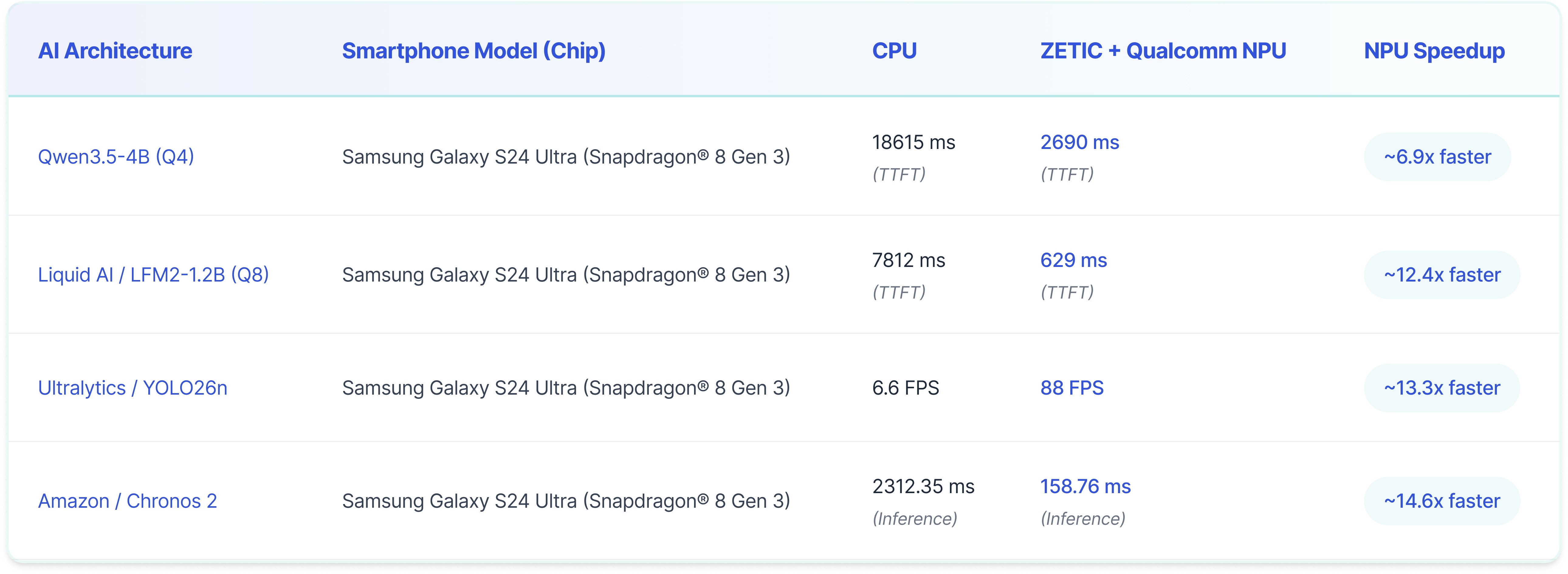
(Note: For Qwen3.5 and Liquid, times represent TTFT or Time To First Token. For Amazon Chronos 2, times represent total Inference Time. For YOLO26n, FPS stands for Frames Per Second. Lower milliseconds and higher FPS indicate better performance.)
By understanding these exact performance leaps, engineering teams can confidently optimize for latency and throughput to ensure they deliver a highly responsive, real-time user experience.
Day 0- Support for Liquid AI's LFM2.5 350M
As part of our collaboration with Qualcomm and Liquid, we are rolling out Day 0 support for LFM2.5 350M through Melange.
Developers can now deploy and run LFM2.5 350M directly on-device, leveraging on-device hardware for efficient inference across CPU, GPU and NPU on real devices. No waiting for ecosystem support, ready to run on-device from day zero. No custom optimization pipelines required.
Here is a snapshot of how LFM2.5 350M performs on real devices (TPS). Each result shows the best-performing processor per quantization type. More extended benchmarks are available on Melange:
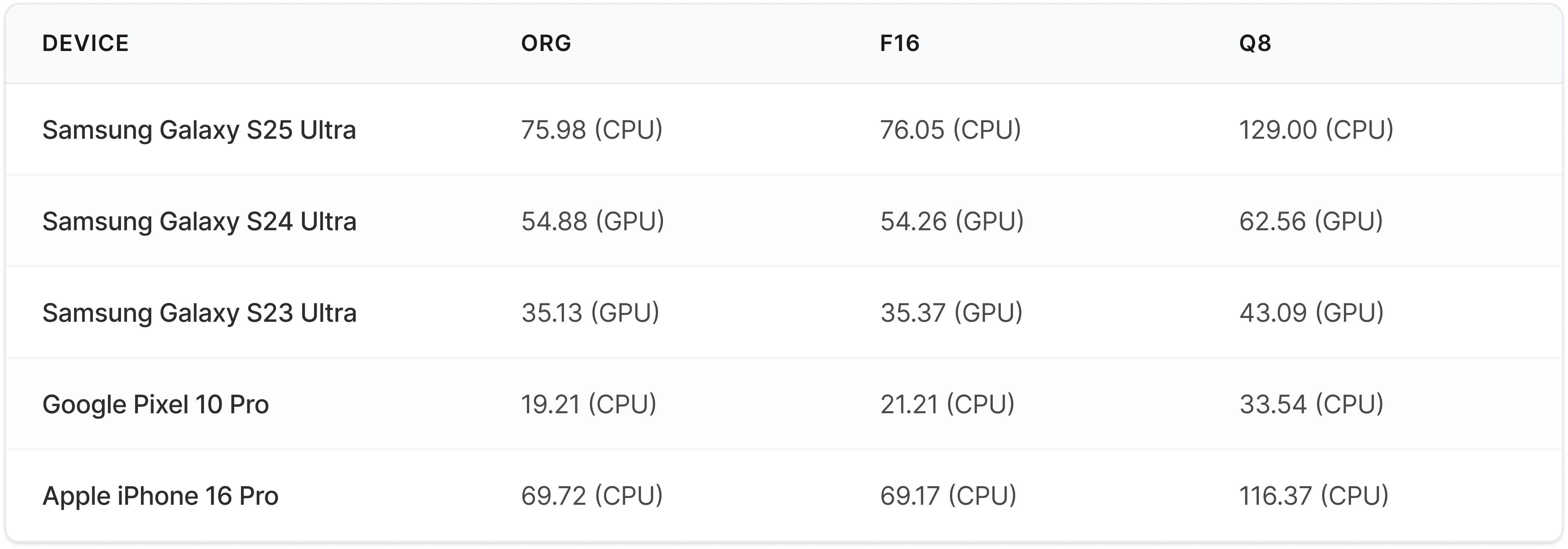
What this enables:
Faster adoption of newly released small language models on Snapdragon devices
Efficient execution across on-device hardware, including CPU, GPU, and NPU
Building AI applications with lower latency, better efficiency, and less dependence on the cloud
The challenge is no longer just model availability. It is how quickly developers can select, benchmark, and deploy those models on real devices. Melange provides a unified on-device execution layer for that, helping developers run models across heterogeneous hardware and benchmark performance across different configurations.
Build for the Edge, Today
The era of relying solely on expensive, latency-heavy cloud compute is over. ZETIC, Qualcomm and Liquid are equipping developers with the tools to build faster, cheaper, and highly performant on-device AI applications.
Try Melange now: https://melange.zetic.ai