Benchmarking solves one problem. Deployment is a different one entirely.

The missing step in on-device AI benchmarking
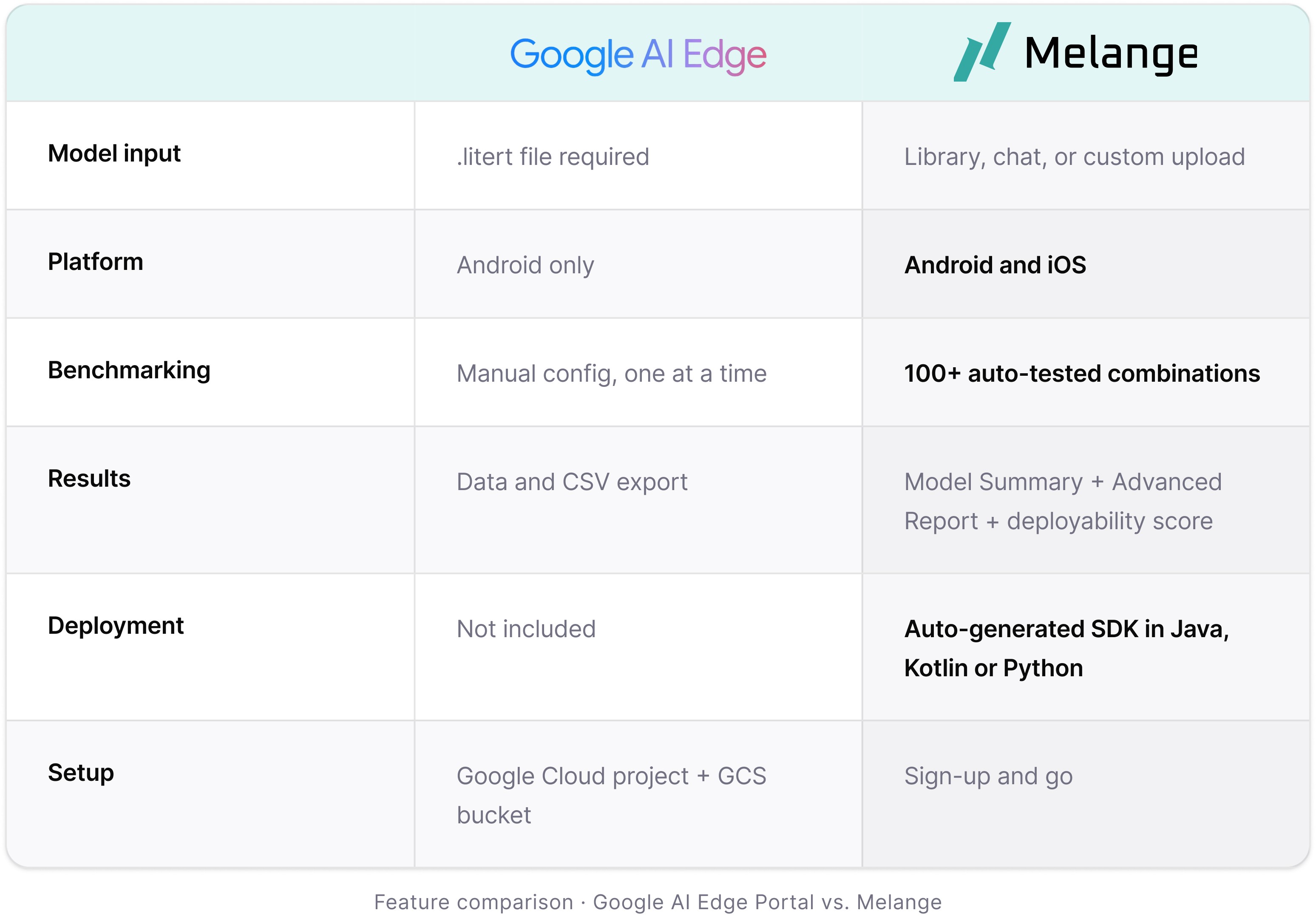
Google AI Edge Portal tells you how your model performs. Melange tells you how to ship it.
On-device AI is having a moment.
Not a hype moment. A real one.
When Google builds dedicated infrastructure for benchmarking AI models on real mobile hardware, it signals something important: the shift from cloud inference to on-device inference is no longer a niche concern. It is becoming a mainstream engineering problem that major platforms are investing in solving.
Google AI Edge Portal, announced earlier this year, is exactly that kind of signal. It lets developers benchmark .litert models across a fleet of over 120 Android devices, testing performance across CPU, GPU and NPU backends at scale. If you are curious, Google published a detailed breakdown here: cloud.google.com/blog/products/ai-machine-learning/benchmark-llms-on-device-with-ai-edge-portal
For the whole on-device AI ecosystem, this kind of investment from a company like Google is a genuinely good thing. It validates the problem space, raises the bar for tooling, and brings more developers into the on-device AI conversation.
We are building in that same conversation. And we want to share how we think about it differently.
The problem both tools are trying to solve
Getting an AI model to run well on a mobile device is harder than it sounds.
A model that performs well in a cloud environment does not automatically perform well on a Snapdragon 8 Elite or an Apple A18. Different chipsets have different NPU architectures. Different runtimes handle quantization differently. A model running FP32 on CPU might be 40x slower than the same model running INT8 on NPU. Without real device testing, you are guessing.
Both Google AI Edge Portal and Melange exist because this problem is real and widespread. Where they diverge is in what they do after you have the answer.
What Google AI Edge Portal does
Based on Google's public documentation and announcement, Google AI Edge Portal is a benchmarking platform that lets developers test .litert models across a diverse pool of Android devices. You select devices, configure your accelerator settings across CPU, GPU or NPU, upload your model, and run a benchmark job. The results give you latency, memory and performance data broken down by device.
For ML teams at large organizations who need rigorous benchmark data to make architecture decisions inside Google Cloud, this is valuable infrastructure.
But based on what Google has publicly shared, the workflow ends at the benchmark. There is no deployment layer. No SDK generation. No path from benchmark results to running code in your app. Getting from those results to a shipped app is still entirely on you.
What Melange does
Melange is a full end-to-end platform for on-device AI deployment. The workflow is three steps: Select, Benchmark, Deploy. Each step flows into the next, in the same platform, without cloud infrastructure setup and without writing low-level hardware code.
Select. You do not need to arrive with a model file ready to go. Browse the public library which includes Gemma, Whisper, LFM2.5, Qwen, YOLO and more, upload your own custom model, or describe what you are building in the chat interface and Melange recommends the right model for your use case. This matters for developers who are not ML researchers. You should not need to already know a model name to start building.
Benchmark. Melange automatically tests your model across 100+ combinations of runtime, quantization, processor and chipset on real devices. Results come in two layers.
The Model Summary gives you a fast read on latency, NPU performance gain, memory and overall deployability score.
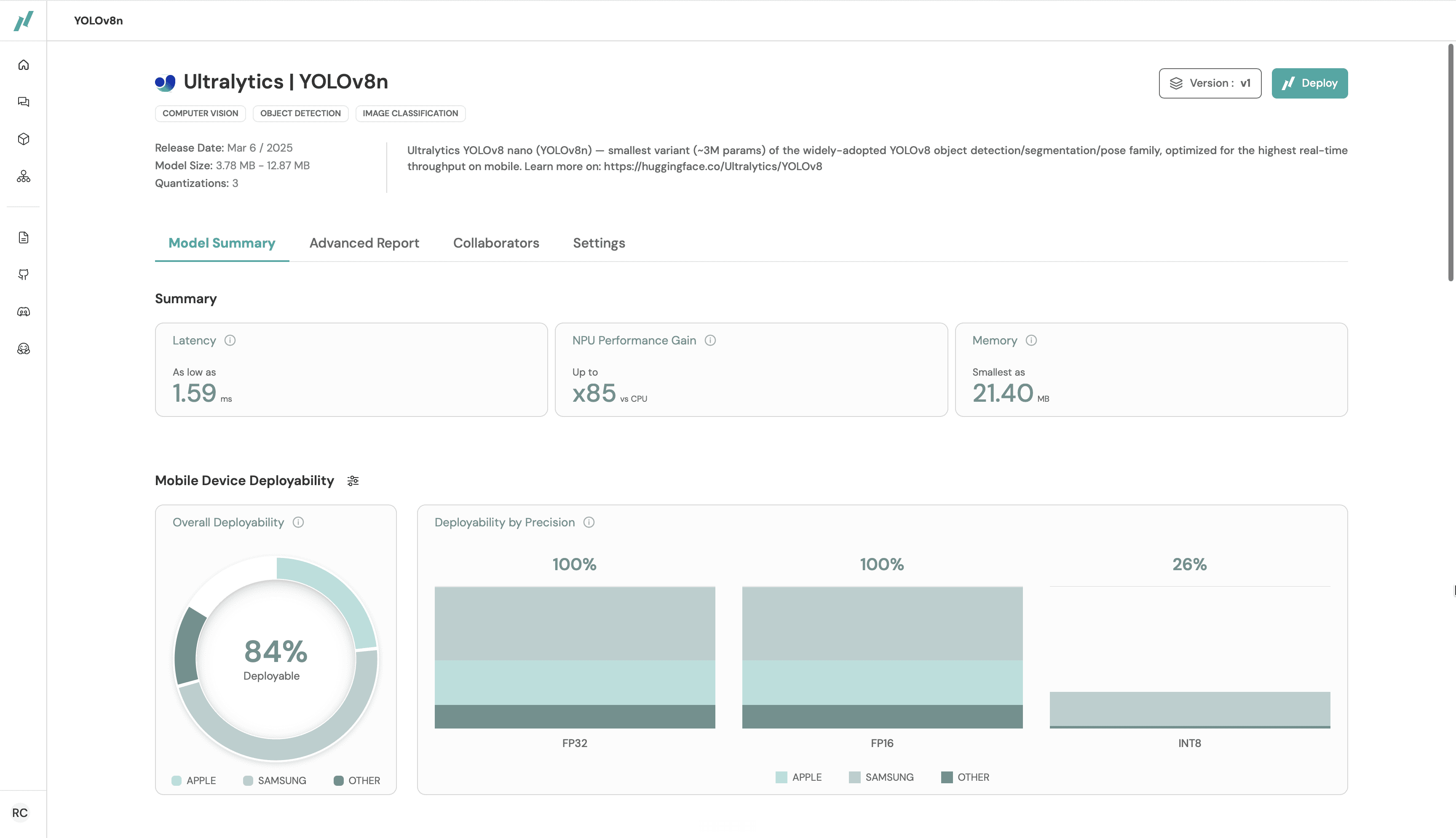
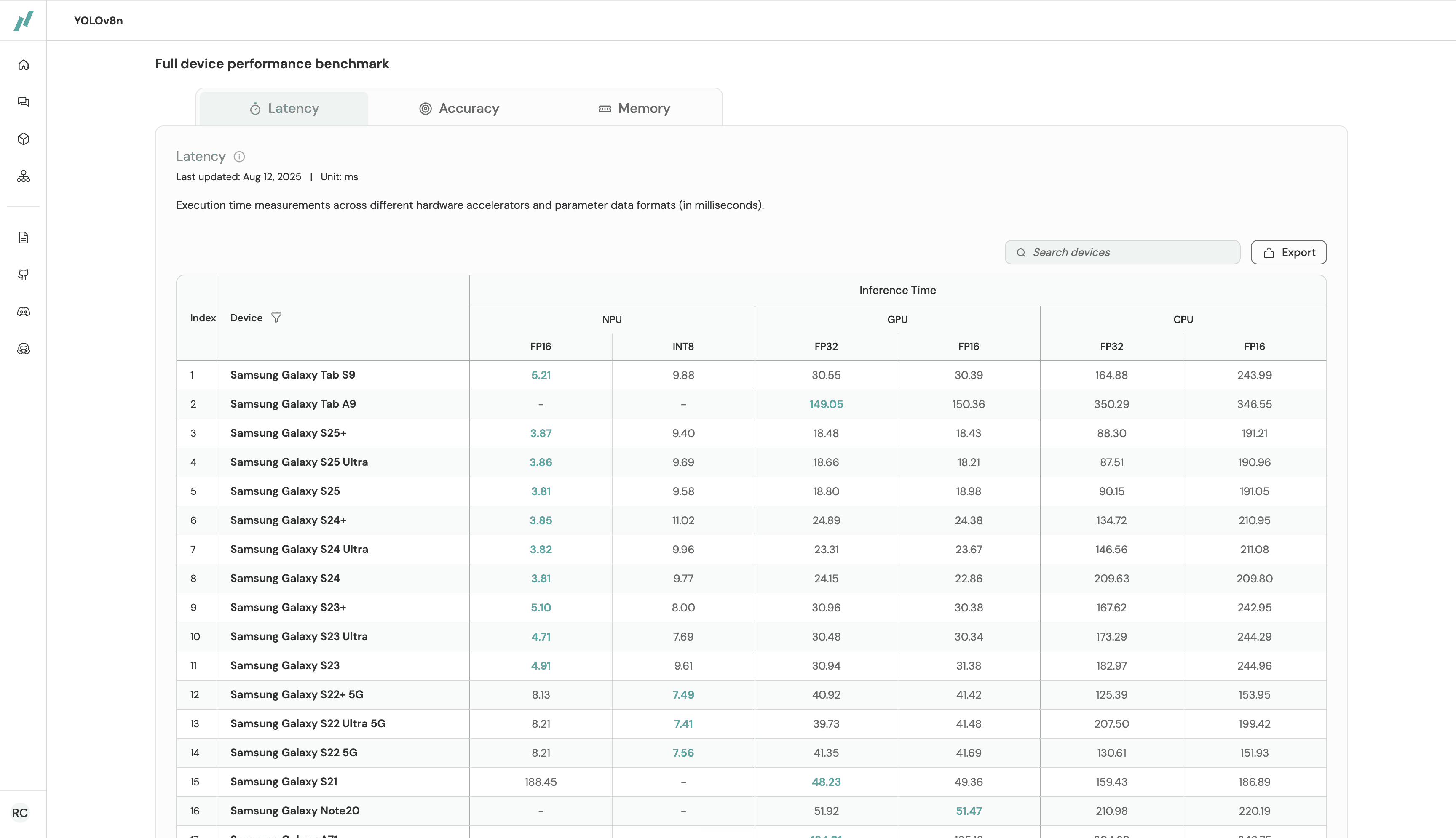
The Advanced Report gives you the full breakdown across NPU, GPU and CPU, with quantization variants including FP32, FP16, INT8, INT4 and more for LLMs, across Qualcomm, MediaTek, Exynos, Google Tensor and Apple chipsets. For enterprise customers, additional data and custom reporting options are available.
Deploy. Select your optimization mode: speed, accuracy or auto. Select your language: Java, Kotlin or Python. Melange generates the SDK code. Copy it, paste it into your app, and ship.

One developer. Hours, not weeks.
The key difference
Benchmarking tells you where you are. Melange takes you where you need to go.
From benchmark to shipped in 16 minutes
When a team at LA Hacks 2026 used Melange to benchmark their custom neural network, they had results across Apple, Samsung, Google and Xiaomi devices in 16 minutes. Running on the NPU via Melange, their model delivered a 26x performance improvement compared to CPU deployment, at sub-millisecond latency with zero cloud dependency. They went from benchmark to shipped demo in a 36-hour hackathon.

That is not a research exercise. That is a deployment platform doing its job. If a student team can go from model to shipped demo in 36 hours, imagine what your team can do with more time.
Two tools, two jobs
Google AI Edge Portal is built for ML teams doing model research inside Google Cloud. It gives you deep benchmark data to inform architecture decisions. The fact that Google built it is good for the whole ecosystem.
Melange is built for developers who need to ship. Select the right model, understand how it performs on real hardware, and get it into production without building your own optimization pipeline from scratch.
If you are building for Android and iOS, you do not need two separate tools or two separate pipelines. One platform, both platforms, same three steps.
The hardware sitting in people's pockets today is more capable than most developers are using it for. The gap has never been the hardware. It has been the tooling.
Melange was built to close that gap. Come see what you can build.
Try Melange: melange.zetic.ai
Documentation: docs.zetic.ai
Community: discord.com/invite/gqhDWfZbgU