On-Device AI for
Everything
On-Device AI for Everything
for any model, on any device, in any framework
for any model,
on any device, in any framework.
On-Device AI
Why run models locally?
Why run models locally?
Running AI models on your mobile device is
Faster, Cheaper, Safer, and Independent
Running AI models on your mobile device is
Faster, Cheaper, Safer, and Independent
Running AI models on your mobile device is
Faster, Cheaper, Safer, and Independent
No Latency
AI runs in real time without cloud latency
No Latency
AI runs in real time without cloud latency
Save Cost
No expensive GPU or Cloud token costs
Save Cost
No expensive GPU or Cloud token costs
Full Privacy
All data stays on your personal device
Full Privacy
All data stays on your personal device
Offline Access
Access from anytime anywhere without internet connection
Offline Access
Access from anytime anywhere without internet connection
No Latency
AI runs in real time without cloud latency
Full Privacy
All data stays on your personal device
Save Cost
No expensive GPU or Cloud token costs in real time without cloud latency
Offline Access
Access from anytime anywhere without internet connection
Our Product
MLange : Provide everything
for your local AI
MLange : Provide everything for your
local AI
A platform that finds the best optimization to deploy your own AI model locally for any device
Running AI models on your mobile device is
Faster, Cheaper, Safer, and Independent
Running AI models on your mobile device is
Faster, Cheaper, Safer, and Independent
Built by AI Engineers & Researchers from
Built by AI Engineers & Researchers from






Streamlined Workflow
Deploy in 3 Simple Steps
Deploy in
3 Simple Steps
Deploy in 3 Simple Steps
Go from raw model file to
active mobile app integration in minutes
Go from a raw model file
to active mobile app integration in minutes
Running AI models on your mobile device is
Faster, Cheaper, Safer, and Independent
Step 1: Upload
Step 2: Benchmark
Step 3: Deploy
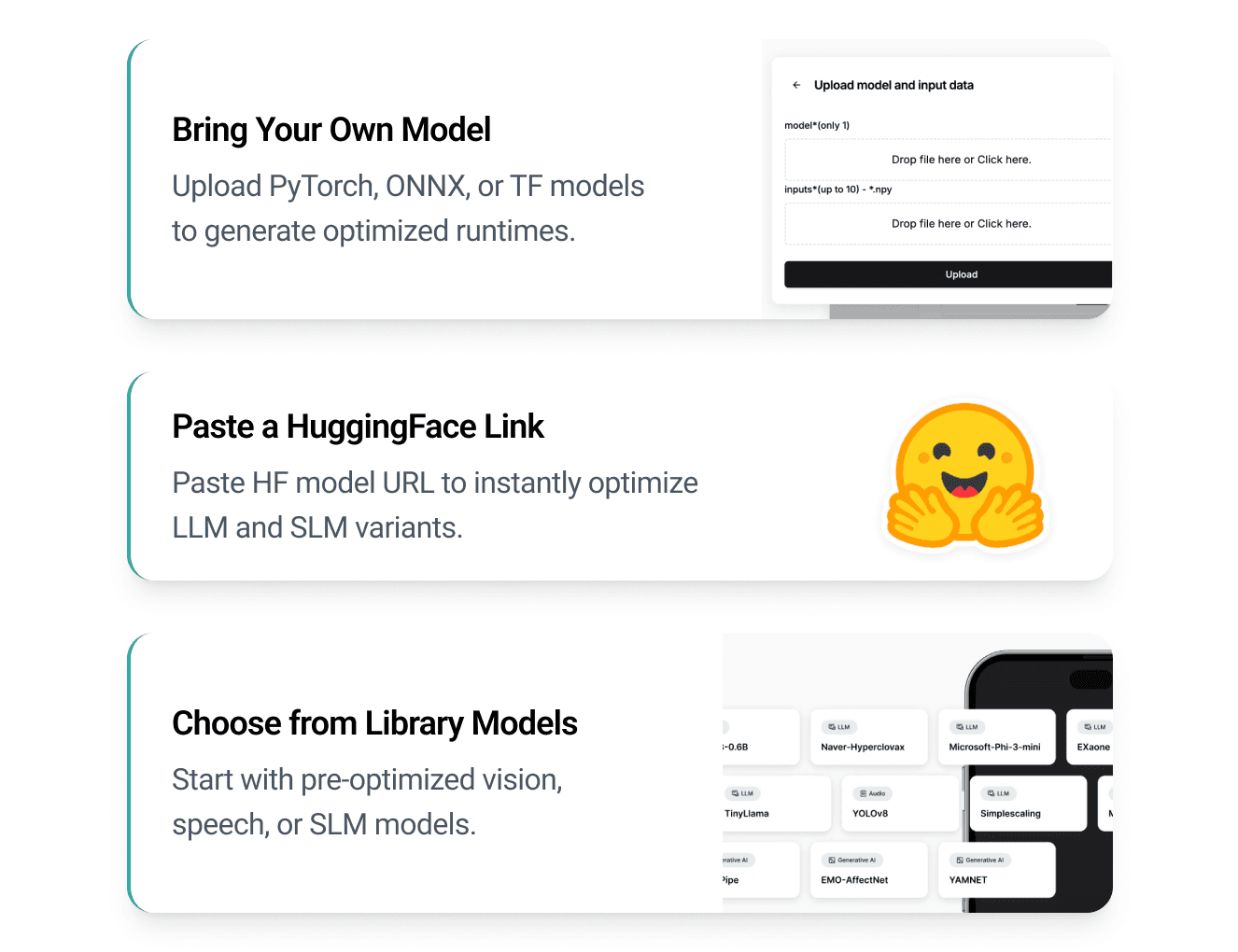
3 Ways to Upload Your Model
Choose the fastest way to get started. Upload your own model, paste a Hugging Face link, or select from our pre-optimized model library.
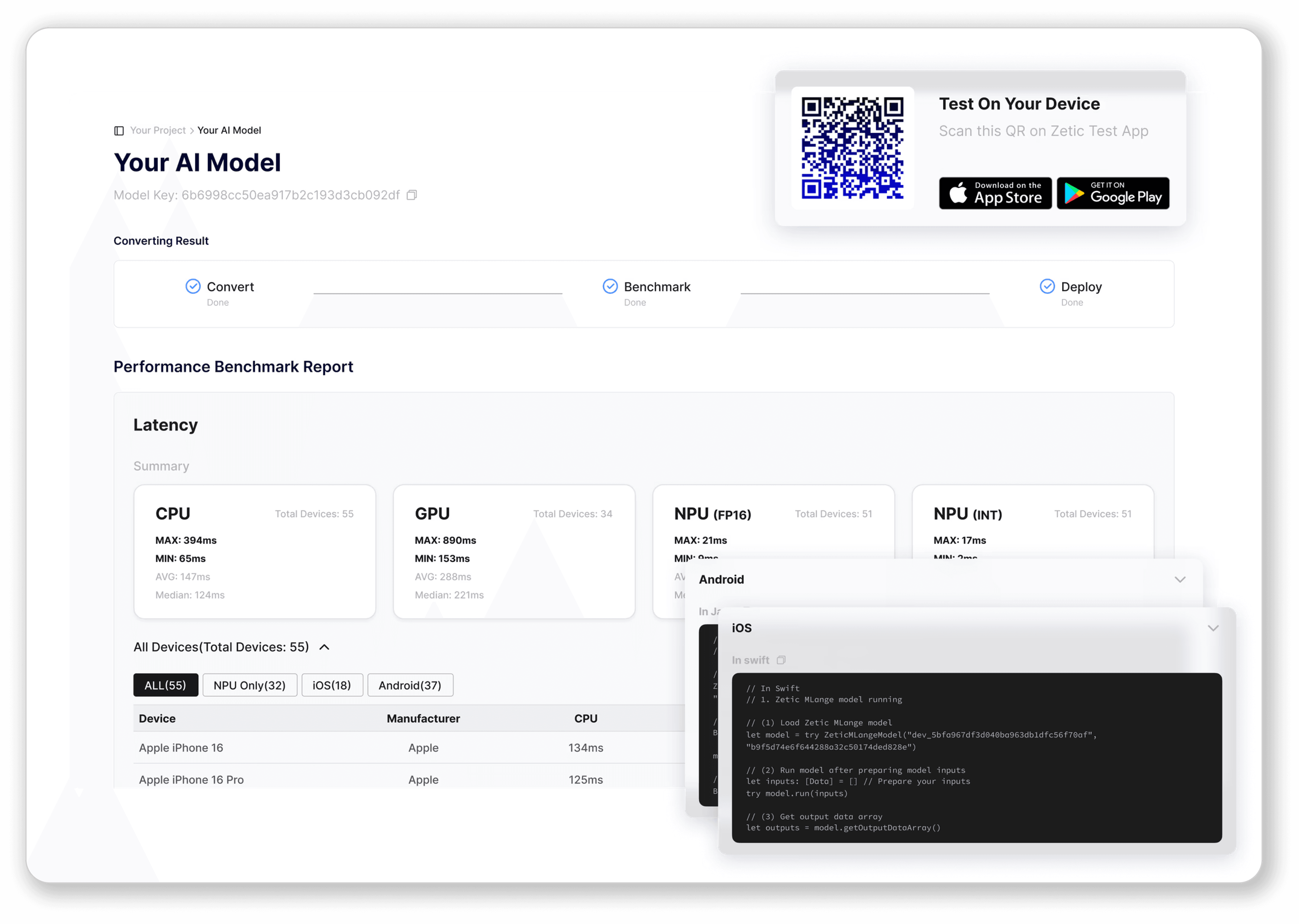
Review Benchmark Report
Check latency and accuracy for each target hardware. Choose the best optimized solution for your case.
Copy Code Block & Deploy
Deploy your model with just 3 simple lines of code! Use a ready-to-integrate code snippet with a loop-based logic.

Step 1: Upload
Step 2: Benchmark
Step 3: Deploy
3 Ways to Upload Your Model
Choose the fastest way to get started. Upload your own model, paste a Hugging Face link, or select from our pre-optimized model library.
Review Benchmark Report
Check latency and accuracy for each target hardware. Choose the best optimized solution for your case.
Copy Code Block & Deploy
Deploy your model with just 3 simple lines of code! Use a ready-to-integrate code snippet with a loop-based logic.
Step 1: Upload
Step 2: Benchmark
Step 3: Deploy
3 Ways to Upload Your Model
Choose the fastest way to get started. Upload your own model, paste a Hugging Face link, or select from our pre-optimized model library.
Review Benchmark Report
Check latency and accuracy for each target hardware. Choose the best optimized solution for your case.
Copy Code Block & Deploy
Deploy your model with just 3 simple lines of code! Use a ready-to-integrate code snippet with a loop-based logic.
Core Capabilities
Quickest & Most Optimized Impact
Quickest & Most Optimized Impact
Quickest & Most Optimized Impact
Cut deployment time from months to hours with automated, hardware-aware optimization
Cut deployment time from months to hours
with automated, hardware-aware optimization
Up to
Up to
Up to
faster
faster than CPU
faster
than CPU
than CPU
Unlock full NPU acceleration instantly. Achieve speed 60x faster than CPU and cut model size by 50% for ultra-low latency.
Unlock full NPU acceleration instantly. Achieve speed 60x faster than CPU and cut model size by 50% for ultra-low latency.
Under 6hrs for
implementation
Only 6hrs for implementation
Under 6hrs for
implementation
Turn raw model files into deployed, hardware-optimized mobile SDKs in under 6 hours, replacing months of manual NPU tuning and fragmented management.
Turn raw model files into deployed, hardware-optimized mobile SDKs in under 6 hours, replacing months of manual NPU tuning and fragmented management.
Optimized for the best performance
Optimized for the best performance
Automated deployment with quantization tailored to any specific NPU architectures. Maximize throughput and preserve accuracy without manual engineering.
Automated deployment with quantization tailored to any specific NPU architectures. Maximize throughput and preserve accuracy without manual engineering.




















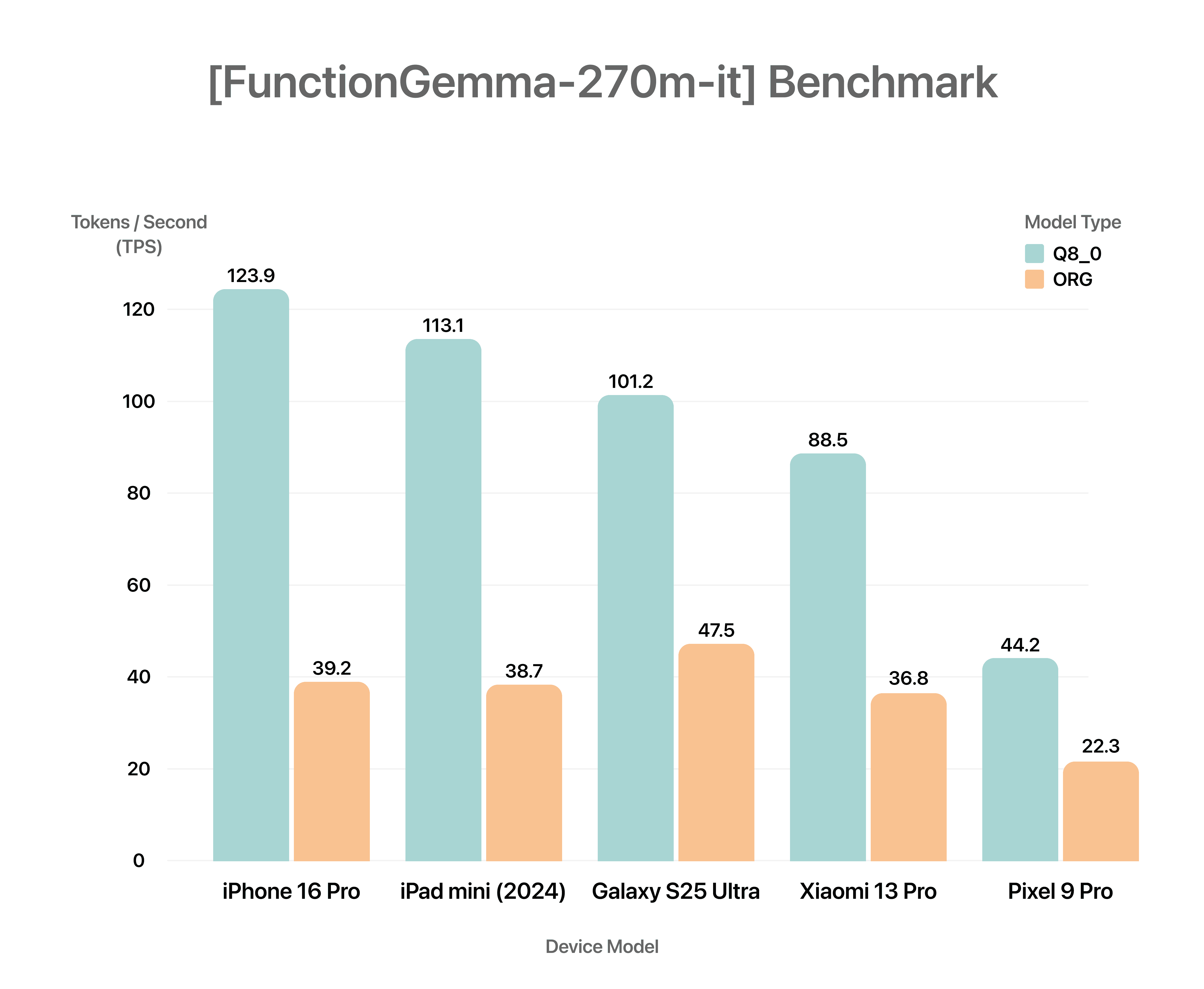
Benchmark on
Benchmark on
Benchmark on
mobile devices
mobile devices
mobile devices
Get granular latency and accuracy reports across 200+ real-world devices before you ship a single line of code.
Get granular latency and accuracy reports across 200+ real-world devices before you ship a single line of code.
The ZETIC Advantage
Why MLange?
Why MLange?
Why MLange?
Replace months of manual CPU tuning with an automated, NPU-accelerated pipeline that deploys in hours
Replace months of manual CPU tuning with
an automated, NPU-accelerated pipeline that deploys in hours.
Feature
Others
Optimization Workflow
Manual
Optimization Workflow
Manual
Optimization Workflow
Manual
Processor Chip Compatibility
Limited (CPU focus)
Processor Chip Compatibility
Limited (CPU focus)
Processor Chip Compatibility
Limited (CPU focus)
Deployment Complexity
Complex Manual Coding
Deployment Complexity
Complex Manual Coding
Deployment Complexity
Complex Manual Coding
Deployment Duration
12+ months
Deployment Duration
12+ months
Deployment Duration
12+ months
Device Testing
Unavailable to verify on global devices
Device Testing
Unavailable to verify on global devices
Device Testing
Unavailable to verify on global devices
Import Model from
Model Library only
Import Model from
Model Library only
Import Model from
Model Library only
MLange
Fully automated pipeline
Fully automated pipeline
Fully automated pipeline
CPU + GPU + NPU hybrid acceleration
CPU + GPU + NPU hybrid acceleration
CPU + GPU + NPU hybrid acceleration
Simple 3-line code deployment
Simple 3-line code deployment
Simple 3-line code deployment
Ready under 6 hours
Ready under 6 hours
Ready under 6 hours
Tested on 200+ devices
Tested on 200+ devices
Tested on 200+ devices
Model Library + Own Model + HuggingFace Models
Model Library + Own Model + HuggingFace Models
Model Library + Own Model + HuggingFace Models
Beyond Mobile Devices
Embedded AI Solutions
Beyond Mobile Devices
Embedded AI Solutions
Beyond Mobile Devices
Embedded AI Solutions
From MCUs to industrial computers
From MCUs to industrial computers
From MCUs to industrial computers
Accelerate Silicon Adoption
Empower clients to benchmark and deploy on your NPUs instantly. Remove technical friction and accelerate your chip sales.
Deploy on Your Infrastructure
Deploy on Your Infrastructure
Need AI in your industrial site? We help you deploy AI models on your infrastructure today.
Need AI in your industrial site?
We help you deploy AI models on your infrastructure today.
Make Your Hardware AI-Ready
Make Your Hardware AI-Ready
Turn your hardware into an effortless AI platform. We handle software integration so your customers can launch without engineering hurdles.
Turn your hardware into an effortless AI platform. We handle software integration so your customers can launch without engineering hurdles.
Accelerate Silicon Adoption
Accelerate Silicon Adoption
Empower clients to benchmark and deploy on your NPUs instantly. Remove technical friction and accelerate your chip sales.
Empower clients to benchmark and deploy on your NPUs instantly. Remove technical friction and accelerate your chip sales.
FAQ
FAQ
Can't find an answer to your question here? Contact us using the link below.
Can't find an answer to your question here?
Contact us using the link below.
Do I need to retrain my model to use ZETIC.MLange?
No. We support TorchScript, TensorFlow and ONNX models directly. Our platform automatically handles conversion and quantization for on-device execution without needing your training data or altering weights
Why use ZETIC.MLange instead of free open-source tools like TFLite or CoreML?
How much cost savings can be achieved by using ZETIC.MLange?
Is on-device AI actually faster than a powerful cloud GPU server?
What happens if a user’s phone is old and doesn't have an NPU?
How difficult is the integration into my existing mobile app?
Do I need to retrain my model to use ZETIC.MLange?
No. We support TorchScript, TensorFlow and ONNX models directly. Our platform automatically handles conversion and quantization for on-device execution without needing your training data or altering weights
Why use ZETIC.MLange instead of free open-source tools like TFLite or CoreML?
How much cost savings can be achieved by using ZETIC.MLange?
Is on-device AI actually faster than a powerful cloud GPU server?
What happens if a user’s phone is old and doesn't have an NPU?
How difficult is the integration into my existing mobile app?
Do I need to retrain my model to use ZETIC.MLange?
No. We support TorchScript, TensorFlow and ONNX models directly. Our platform automatically handles conversion and quantization for on-device execution without needing your training data or altering weights
Why use ZETIC.MLange instead of free open-source tools like TFLite or CoreML?
How much cost savings can be achieved by using ZETIC.MLange?
Is on-device AI actually faster than a powerful cloud GPU server?
What happens if a user’s phone is old and doesn't have an NPU?
How difficult is the integration into my existing mobile app?
Begin today
Begin today
Begin today
Ship your first
on-device AI App today
Ship your first
on-device AI App today
Start benchmarking and deploying in minutes.
No credit card required for the free tier
Start benchmarking and deploying in minutes.
No credit card required for the free tier